Table of Contents (click to expand)
Essentially, pausing is merely a request to the server for a new download. This download starts from where the previous download was “paused”.
We’re living in the age of the information revolution, where data has gained the same importance once enjoyed by oil, electricity, and religion. Every aspect of life can be quantified into data in some form or another. Everything we do is either logged into a database by some authority for regulation or surrendered voluntarily by allowing the apps we use to access our information.
Data is also now much more accessible to the general public, whether in the form of information or multimedia files, such as video games, movies, or music. Video games, for instance, used to be a highly gate-kept form of entertainment. Available only to enthusiasts who could afford the games, along with systems that could run them, video games were an elite activity.

However, video games are now one of the most prevalent forms of entertainment. You can play them on your smartphones, laptops, or dedicated consoles. Additionally, since the internet is so widely accessible, there’s no shortage of ways to surpass paying for whatever you want to play. Piracy has been around for almost as long as the internet has been publicly accessible. Any user who knows how to access the domain of a pirated data host can download and use that data.
Recommended Video for you:
Data: Behind The Scenes
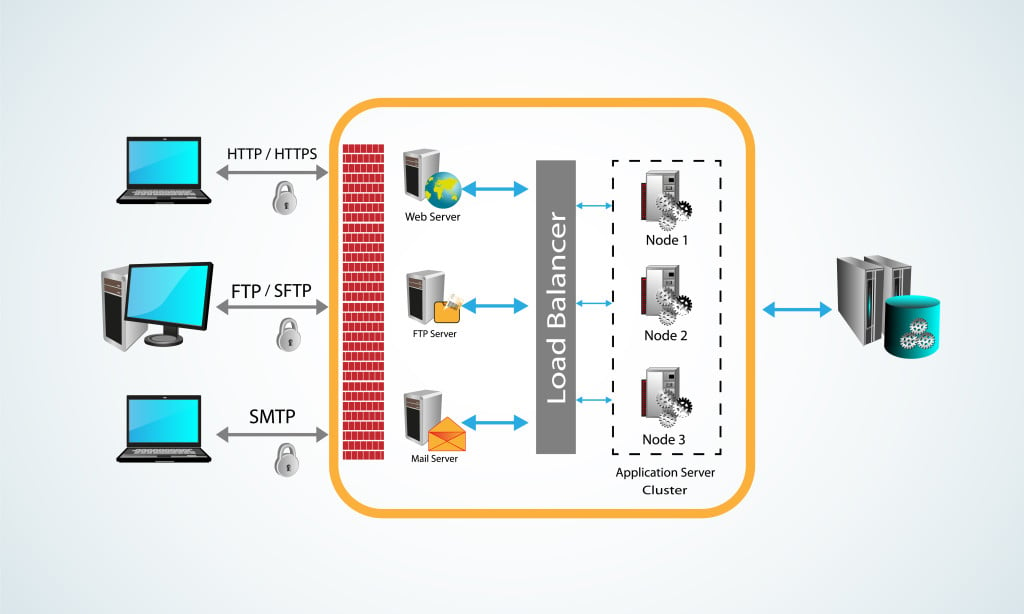
All data is stored on servers. A modern data server is a combination of two things:
- Hardware with enough storage and power to store the file in question and to transfer that file to whoever asks for it. This system is known as the host.
- Software that makes the host’s database available to other users as downloadable data, such as a website.
But the question here is: How do these downloads work? And, obviously, how are downloads paused?
To answer these questions, we will have to look at the concept of data and, specifically, how to download from a coding perspective.
How Do Computers Process Data?
All information is stored in a computer in the form of bits. A bit is the smallest unit of data that a computer can process and store; it is in the form of a binary digit. Its value can be either 0 or 1. This 0 or 1 can also be interpreted as a yes/no or a true/false, similar to a light’s on/off switch.

Now, 8 bits together make a byte. A byte is basically any data that is fed to a computer and translated into a language that the computer can process and store. These bytes can be stored in the computer in data structures, such as arrays, stacks, lists, etc., to help the computer process them more efficiently.
How Do Downloads Work?
A download, from a coding perspective, is nothing but a byte array. It is a collection of data stored in a computer that, along with its linked data, can form a game, a movie, a document, or anything that its creator made it to be. The process of downloading is nothing but a file transfer from the server to the client, which is the system downloading the file.
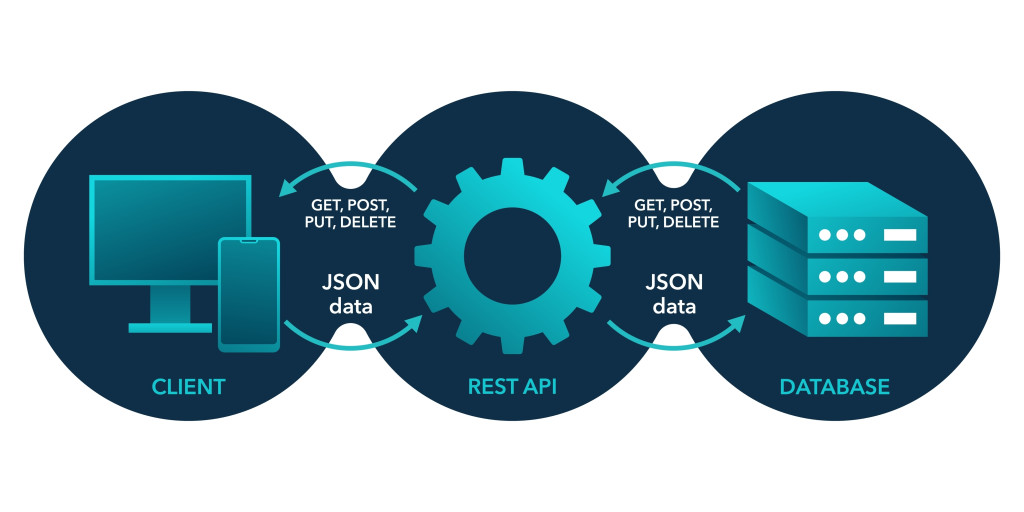
There are two primary protocols or methods to download a file:
- File Transfer Protocol (FTP): This is the method primarily used to transfer files, such as images, movies, etc. This is older and uses a protocol known as Transmission Control Protocol (TCP), which prioritizes security. I won’t delve further into explaining these protocols, as that is a deep rabbit hole you don’t need to explore to find the answer you’re seeking. A fun tidbit, however, is that User Datagram Protocol (UDP)[6] is the newer version of TCP that prioritizes speed and is used by sites to stream movies and videos from their host server.
- HyperText Transfer Protocol (HTTP): This is the basis for the World Wide Web. Just as FTP is used for transferring files, HTTP is used for transferring web pages, and it defines how a web page will respond to any request. This is why most web addresses contain http:// at the start, since this defines the website’s protocol. This also uses TCP.

A request for a download is a simple ‘GET’[7] request. In either of these methods of downloading, when you request a download, you have to specify the destination folder for the download to be stored on your system, such as the “downloads” folder. Once the connection between your system and the host server is established, your computer assigns the space required by the file at that destination. The file is then transferred from the host server to your system, according to the speed and stability of your connection.
“Pausing” this download is just you terminating the connection between the host server and your system. Instead, you want to ask, “How does resuming downloads work?”
How Does Pausing Downloads Work?
The HTTP and FTP protocols contain a “Range” specification, where your system can request only a specific part of the download. So, if you’ve paused the download at 4,000 out of 18,000 bytes, your system will request the server for only the 4,001st to the 18,000th byte when you resume the download.
Your system recognizes that you’re downloading a partial file by sending a ‘HEAD’[8] request (a quicker form of a ‘GET’ request). If code 206 is returned in response to the request, the system recognizes it as a partial download.
Effectively, the only difference between pausing and completely stopping a download is that, while pausing, the server doesn’t terminate its connection to the client so that it can check the validity of the already downloaded files before it approves the request for the remaining files, in order to make sure that the download doesn’t get corrupted.
Another interesting tidbit: Coders use a system called Hashing to ensure that the data they’ve downloaded is not corrupted. A hash is a label assigned to the downloaded file on your computer, and to resume this download or check its validity, the host server simply checks for this hash.